
Accuracy Metrics for Detecting Online Harassment
Online harassment is a growing problem, especially for public figures and professionals. Automated detection tools are essential to address this issue, but their effectiveness depends heavily on the right accuracy metrics. Here’s what you need to know:
- Metrics like precision, recall, F1 score, and AUC are used to measure how well systems identify harmful content.
- High recall is crucial for detecting threats in private messages, ensuring dangerous content doesn’t go unnoticed.
- High precision is better for public comment moderation to avoid flagging legitimate interactions.
- Imbalanced datasets can distort accuracy, making advanced metrics like AUC-ROC and PR-AUC more reliable.
- Multilingual platforms face unique challenges with cultural and linguistic nuances, requiring tailored datasets and testing.
Guardii, a moderation tool, uses these metrics to balance user safety with engagement. It prioritizes high-recall models for private threats and high-precision models for public content, while providing tools like evidence packs and repeat-offender tracking to enhance accountability and efficiency.
Cyberbullying Detection using Ensemble Method
Core Accuracy Metrics for Harassment Detection
Core Accuracy Metrics for Online Harassment Detection Systems
Understanding Accuracy, Precision, Recall, and F1 Score
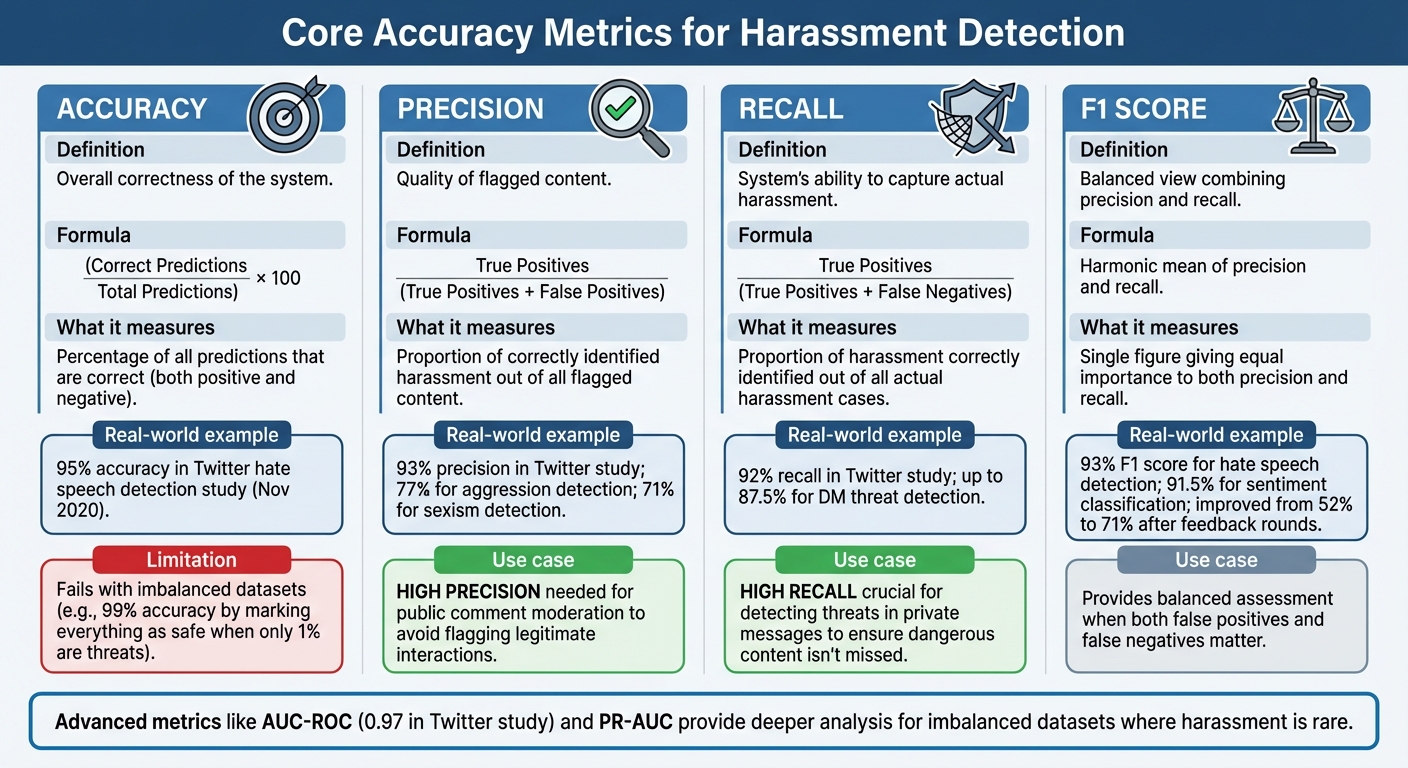
Detection systems rely on four key metrics to gauge their performance. Accuracy reflects the overall correctness of the system - essentially, the percentage of predictions that are correct, whether positive or negative. Precision, on the other hand, focuses on the quality of flagged content. It measures the proportion of correctly identified harassment (True Positives) out of all flagged content (True Positives + False Positives). Recall shifts the lens to the system's ability to capture actual harassment. It calculates the proportion of harassment correctly identified (True Positives) out of all actual harassment cases (True Positives + False Negatives). Finally, the F1 score provides a balanced view by combining precision and recall into a single figure, using their harmonic mean to give equal importance to both.
For example, a November 2020 study on machine learning techniques for hate speech detection on Twitter highlighted these metrics. The system achieved an accuracy of 0.95, precision of 0.93, recall of 0.92, and an F1 score of 0.93 for detecting hate speech. When it came to hate speech sentiment classification, the F1 score reached 91.5%. These results show how these metrics, while interconnected, can reveal different facets of a system's performance. However, these metrics can become misleading when threats are rare, as the next section explains.
Why Accuracy Alone Fails in Imbalanced Datasets
Although accuracy is a straightforward metric, it often fails in scenarios where data is imbalanced. For instance, if only 1% of comments on a platform contain threats, a system that labels every comment as safe would achieve an impressive 99% accuracy - while completely failing to catch any harassment. In such cases, high accuracy can mask a system's inability to detect rare but critical threats.
This issue is especially problematic in real-world moderation. Automated systems may fail to protect users from abusive content while also censoring legitimate speech. The challenge is compounded by the complexity of abusive language, which often depends on perception and context, falling into ambiguous "gray areas". Additionally, datasets used to train these systems frequently suffer from selection bias, causing models to rely on surface-level cues - like specific words - that aren't inherently abusive.
Advanced Metrics: AUC-ROC, PR-AUC, and Specificity
To overcome the limitations of basic metrics, advanced tools offer a deeper analysis of model performance. These are especially useful when systems generate confidence scores instead of binary decisions.
AUC-ROC (Area Under the Receiver Operating Characteristic curve) evaluates how well a model separates classes across various thresholds. This metric is particularly helpful in safety-critical applications or when working with imbalanced datasets, as it avoids committing to a single decision threshold. For example, the Twitter hate speech detection system achieved an AUC of 0.97, showing strong ability to distinguish between hate speech and non-hate speech across different levels of confidence.
PR-AUC (Precision-Recall Area Under the Curve) zeroes in on the balance between precision and recall, making it ideal for imbalanced datasets where harassment is rare. Specificity (True Negative Rate) measures how well the system correctly identifies non-harassment content as safe. This is crucial for minimizing false positives that could stifle legitimate conversations. Additionally, the F-beta score extends the F1 score by allowing precision and recall to be weighted differently. It is calculated as (1 + β²)(Precision × Recall)/(β² × Precision + Recall), making it adaptable for situations where one type of error - like missing harassment or over-flagging content - is more costly than the other.
Tradeoffs Between Safety and Engagement
High Recall for Threats and Direct Message Harassment
When it comes to tackling direct message threats and sexual harassment, the priority is maximizing recall - even if it means dealing with more false positives. Why? Because missing a real threat can have serious consequences. Under California law, online threats are treated just as seriously as those made in person. And the mental health impacts of cyberbullying are no small matter. Ignoring or missing these threats can lead to harm that legal action might only address after the damage is done.
This approach - favoring high recall - means more flagged content, but it ensures that real threats are less likely to slip through the cracks. For individuals like athletes, journalists, and public figures who receive a flood of direct messages, the risk of missing a credible threat far outweighs the hassle of reviewing a few extra flagged messages. As Anna Maria Chavez aptly put it:
Unless and until our society recognizes cyber bullying for what it is, the suffering of thousands of silent victims will continue.
This method, however, stands in stark contrast to the precision required for managing public interactions.
High Precision for Genuine Engagement
On the flip side, public comment moderation demands high precision. The goal here is to protect authentic interactions while filtering out harmful content. Mislabeling humorous or passionate comments as inappropriate can stifle engagement and even lead to unnecessary legal complications. For sports teams, influencers, and other public figures, over-moderation risks alienating fans and damaging relationships.
An industry analysis highlights this challenge. It found a 77% precision rate for detecting aggression and a 71% precision rate for identifying sexism on Twitter. While these numbers reflect progress, they also reveal that nearly one in four flagged comments might be legitimate. High recall might catch more harmful content, but high precision ensures that meaningful conversations and fan interactions remain intact. As The Law Offices of Kerry L. Armstrong, APLC explains:
civil society cannot tolerate online harassment.
Platforms must carefully adjust their systems to strike the right balance between safety and authentic engagement.
Evaluating Real-World Impact
Finding the right balance between recall and precision requires looking at real-world performance metrics. For instance, missed incident rates show how much harmful content slips through, directly reflecting a platform's ability to ensure user safety. Meanwhile, review workload measures the strain on moderators and the potential disruptions to genuine interactions. Moderation speed is another critical factor - it’s about addressing threats quickly while ensuring legitimate content gets processed without delay. Together, these metrics provide a clear picture of how well a platform protects users while keeping online spaces lively and engaging.
sbb-itb-47c24b3
Validation Methods and Dataset Management
Validation Techniques: Train-Test Splits and Cross-Domain Testing
Harassment detection models need more than basic train-test splits for evaluation. Why? Because a model that excels in one domain can fall short in another. For instance, a model trained on U.S. English often struggles with Nigerian English dialects, leading to overly optimistic performance metrics that don’t align with real-world outcomes.
Research shows that biased datasets can exaggerate performance estimates by up to double in real-world scenarios. This discrepancy underscores the importance of cross-domain testing. Models should be tested on data that mirrors their intended use cases - whether analyzing Instagram comments from European football fans or handling messages sent to journalists in Southeast Asia. Using human-in-the-loop pipelines with iterative feedback cycles ensures greater reliability by refining both gold-standard and noisy labels. After each feedback round, dynamic evaluation with metrics like F1 score and Cross Entropy helps track how well the model adapts to human corrections. Such strategies are essential for building robust models that can handle diverse linguistic and cultural contexts.
Managing Imbalanced Datasets with Rare Harms
Severe harassment is rare, making it a challenge for standard training methods. One solution is active-learning correction, where human evaluators refine machine-generated labels through targeted feedback. This approach becomes even more effective when paired with model-generated explanations that clarify why a text was flagged, helping annotators achieve greater consistency - especially when dealing with subtle or culturally specific language.
Another key tactic involves leveraging expert annotators with deep domain knowledge. Native speakers familiar with social media nuances can better differentiate personalized cyberbullying from general hate speech. For particularly tricky cases, requiring multiple annotators to reach a consensus minimizes subjectivity. These methods help prevent models from relying too heavily on non-abusive "cue words", enabling them to generalize more effectively across the wide spectrum of online harassment. Beyond addressing imbalanced datasets, it’s crucial to account for linguistic and demographic diversity.
Multilingual and Demographic Factors in Dataset Design
What’s considered harmful or toxic often varies significantly across cultures and demographics. Selection bias can lead models to overemphasize neutral cue words, unintentionally reinforcing demographic biases. In multilingual contexts, annotator perspectives and cultural nuances add another layer of complexity, making diverse annotation teams and type-aware classifiers indispensable.
For platforms operating in over 40 languages, it’s vital to test models on representative samples from each linguistic and cultural context. A system optimized for English-language sports banter might completely overlook threats expressed in Arabic slang or misinterpret enthusiastic Brazilian Portuguese comments as aggression. By using type-aware classifiers for specific harassment categories - such as sexual, racial, or political abuse - models can better identify key indicators and improve accuracy.
How Guardii Applies Accuracy Metrics
High-Recall Detection for DM Threats and Harassment
Guardii focuses on high-recall models to tackle direct message (DM) threats and harassment, particularly those involving sexual content. The goal? To catch as many harmful messages as possible. Research shows that these models can achieve detection rates of up to 87.5%. To ensure both thorough detection and accurate review, Guardii uses a two-queue system for flagged messages.
- Priority Queue: Urgent threats like stalking, doxxing, or explicit content are flagged here. Alerts are sent directly to teams via collaboration tools for immediate action.
- Quarantine Queue: Messages flagged with lower confidence are held here for additional review.
This layered system aligns with multilingual standards, ensuring that serious threats aren’t overlooked, especially in diverse language contexts.
Precision-Focused Comment Moderation
When it comes to Instagram comments, Guardii shifts gears to a precision-focused model. The aim is to reduce false positives while maintaining genuine user interactions. These precision-optimized models deliver impressive results, achieving precision levels as high as 92% with false positive rates as low as 2.2%.
Guardii automatically hides toxic comments across 40+ languages in line with Meta’s guidelines. Teams can then easily manage these flagged comments with one-click options to unhide, delete, or report. This approach ensures that nuanced conversations, which might vary across languages, are less likely to be wrongly flagged.
Evidence Packs and Repeat-Offender Tracking
Guardii takes its moderation tools a step further by creating evidence packs and audit logs. These detailed records provide transparency and accountability for legal, safety, and compliance teams. On top of that, repeat-offender watchlists allow teams to monitor and address users who repeatedly engage in harmful behavior.
Conclusion
Accuracy metrics play a key role in the effectiveness of online harassment detection. They help differentiate between models that overlook critical threats and those that actively protect vulnerable users. For instance, a case study demonstrated how an SVM model's F1 score improved from 52% to 71% after five rounds of feedback. As Huriyyah Althunayan and colleagues from King Saud University explained:
Overall, using both hard and soft metrics helps with making trade-off judgments as the evaluator is informed about the reliability of labeling during each iteration.
Striking the right balance between recall and precision is crucial. High recall ensures that dangerous threats, such as harmful direct messages or harassment, are detected, while high precision minimizes the mislabeling of legitimate conversations. Both metrics are indispensable - one safeguards users, and the other maintains authentic interactions.
Guardii employs a high-recall approach for identifying threats in direct messages and prioritizes precision for moderating comments. Features like evidence packs and audit logs provide transparency and accountability, ensuring trust in the process.
For athletes enduring targeted abuse, creators managing large, diverse audiences, and organizations safeguarding their brand reputation, these metrics offer tangible advantages. They reduce overlooked threats, limit the misclassification of valid content, and provide solid evidence for handling escalations. Together, these efforts contribute to safer online spaces where users can feel protected without compromising meaningful connections.
FAQs
Why is it important to prioritize high recall when detecting threats in private messages?
High recall plays a key role in spotting threats in private messages because it ensures that most genuine threats are caught and flagged. This minimizes the risk of false negatives, where real threats could slip through unnoticed, potentially leading to serious consequences.
Although prioritizing high recall might sometimes lead to more false positives, this trade-off is often necessary in sensitive areas like detecting online harassment. Identifying as many threats as possible is essential for safeguarding users and ensuring their safety, especially in spaces where personal well-being and reputations are on the line.
How do metrics like AUC-ROC and PR-AUC enhance the accuracy of online harassment detection?
Metrics like AUC-ROC and PR-AUC are essential for assessing how well a model performs across various decision thresholds, especially in the context of detecting online harassment. AUC-ROC measures how effectively a model can differentiate between classes, while PR-AUC zeroes in on precision and recall - key factors when identifying rare but harmful behaviors such as harassment.
These metrics help researchers refine models to minimize both false positives and false negatives, making detection more accurate. This ultimately contributes to creating safer online spaces and offering stronger protection for individuals and communities.
What are the challenges in detecting online harassment across multiple languages?
Detecting online harassment on platforms that support multiple languages is no easy task. A major hurdle lies in the lack of sufficient training data for many languages, particularly regional or low-resource ones. Without this data, building accurate detection models becomes a real challenge. The situation gets even trickier with code-mixed content, where users mix two or more languages in a single comment. Handling such content requires advanced cross-lingual models capable of navigating this linguistic complexity.
Social media posts add another layer of difficulty. Informal spelling, the use of emojis, and slang specific to certain groups or regions can make it tough for automated systems to tell the difference between casual, harmless expressions and genuinely harmful content. On top of that, the meaning of harassment can shift depending on the cultural or situational context, leading to inconsistencies in how content is labeled. This often results in systems flagging too much or too little, creating false positives or negatives.
Fairness and bias also pose serious concerns. Detection systems that are trained mainly on dominant languages may misinterpret or unfairly target underrepresented groups. This underscores the importance of creating solutions that are more inclusive and balanced in their approach.