
Bias in AI Moderation: How to Reduce It
AI moderation systems are essential for managing online interactions, but they often face challenges like bias, which can harm users and brands. Bias occurs when moderation algorithms unfairly flag or overlook content due to issues like unbalanced training data, lack of context understanding, or feedback loops that reinforce errors. This can lead to over-censoring harmless content, missing real threats, and damaging trust in platforms.
Key takeaways:
- Bias sources: Imbalanced datasets, poor handling of language nuances, and self-reinforcing algorithms.
- Detection methods: Use metrics like demographic parity, false positive/negative rates, and explainable AI tools to identify bias.
- Solutions: Build diverse datasets, use adversarial debiasing, and incorporate human review for complex cases.
Reducing bias requires regular audits, transparency, and continuous updates to ensure moderation systems protect users without unfairly silencing them. Tools like Guardii are setting examples by focusing on multilingual moderation, context-aware decisions, and providing evidence for legal or operational needs.
Combating AI Bias at Scale | Jigsaw

Main Causes of Bias in AI Moderation
Bias in AI moderation arises from skewed training data, a lack of cultural understanding, and self-reinforcing algorithmic patterns. These issues become especially problematic when moderating content for global audiences.
Imbalanced Training Data
AI moderation often stumbles when training data leans heavily toward English and Western-centric content. This imbalance makes it harder for systems to fairly assess interactions in other languages or cultural contexts. For instance, a model trained predominantly on English might misinterpret harmless slang in Arabic, Portuguese, or Korean as offensive, or fail to detect actual harmful content in those languages.
Consider the case of influencers or public figures who receive comments in multiple languages. A moderation system trained on a single linguistic group may incorrectly flag benign expressions or, worse, miss genuine threats. Research from Chapman University highlights this issue, showing that biased datasets can lead to systematic misclassification of content from minority groups. For brands managing global communities, this inconsistency can alienate users and erode trust.
But it’s not just about the data itself - cultural nuances also play a critical role in moderation outcomes.
Missing Linguistic and Cultural Context
Even AI systems with multilingual capabilities often lack the cultural awareness needed to interpret content accurately. For example, sports-related slang like "beast mode" or "trash talk" might be flagged as toxic without understanding the playful tone behind them. On the flip side, reclaimed slurs or region-specific idioms could be mistakenly labeled as offensive.
When moderation systems fail to account for these nuances, they risk applying a universal standard to all content. This one-size-fits-all approach can lead to over-flagging harmless remarks and under-flagging harmful behavior. In global communities, such missteps undermine user confidence, as genuine expressions are censored while real threats slip through. This not only damages user trust but also compromises brand safety.
How Algorithms Amplify Existing Bias
The problem doesn’t end with data and cultural gaps - algorithmic feedback loops can make biases even worse. When a model disproportionately flags content from certain groups due to training imbalances, this flagged data often feeds back into the system during retraining. The result? The original bias becomes even more entrenched.
A University of Washington study offers a striking example: an AI hiring system showed significant bias in its recommendations, and human decision-makers ended up following the AI’s choices about 90% of the time. A similar pattern occurs in content moderation. If a system routinely over-flags language patterns associated with minority communities, human moderators may start relying on these automated flags, further reinforcing the bias.
Moreover, AI systems optimized for overall accuracy tend to favor majority patterns, leaving underrepresented groups at a disadvantage. This means moderation systems perform well for dominant language and cultural norms but struggle with niche or minority communities. For global audiences, these amplified biases don’t just affect individual users - they shape public discourse, harm creator wellbeing, and strain relationships with sponsors.
How to Detect Bias in AI Moderation Systems
After understanding where bias originates, the next step is to focus on systematic detection. Without clear metrics and tools for transparency, bias can remain hidden - and unresolved. Organizations must adopt structured approaches to identify disparities before they impact users or erode trust in the brand.
Using Metrics and Audits to Measure Bias
Detecting bias means examining how your moderation system treats different groups. The aim is to ensure that similar content is handled consistently, regardless of the user’s identity or language.
One straightforward metric is demographic parity. This involves calculating the percentage of content flagged or hidden for each group and comparing the results. For instance, if 15% of English-language comments are auto-hidden, but 35% of Spanish-language comments are flagged despite similar policy-violation rates, that’s a clear warning sign. For U.S.-based brands managing multilingual communities, such inconsistencies can alienate large portions of their audience.
Another key measure is analyzing false positive and false negative rates across groups. By reviewing moderation decisions with expert oversight - without revealing the AI's initial choice - you can identify patterns of incorrect flagging. For example, if African American English speakers experience higher false positive rates compared to standard English speakers, it suggests bias in the dataset or model. Studies confirm that biased training data often leads to such systematic errors.
A more advanced metric, equalized odds, digs deeper by assessing whether true positive and false positive rates are consistent across groups for the same type of violation. If your system identifies 80% of hate speech aimed at one community but only 50% targeting another, it creates unequal protection and raises fairness concerns.
To make this process actionable, develop dashboards that break down these metrics by factors like language, region, age group, and content type. Conduct audits regularly - quarterly at a minimum - and continuously in high-risk situations, such as during major events when direct messages (DMs) see spikes in activity. This approach transforms bias detection into an ongoing governance practice. Once bias is measured, the next step is using transparency tools to uncover its root causes.
Explainable AI Tools for Transparency
Metrics highlight where bias exists, but understanding why it happens requires deeper analysis. Explainable AI (XAI) tools can pinpoint the words, phrases, or patterns that most influenced a moderation decision, helping trace errors back to their origins.
Using feature attribution methods like SHAP or Integrated Gradients, you can identify specific tokens - such as reclaimed slurs or nicknames like "beast" - that disproportionately impact toxicity classifications. Examining false negatives can also reveal when the model overlooks nuanced forms of harassment, such as coded language or subtle hate speech.
Example-based explanations take this further by retrieving training examples that influenced similar decisions. If harmless trash talk is frequently flagged because the model over-learned from skewed training data - perhaps an overrepresentation of toxic examples in one dialect - these tools can help uncover and address the issue.
For instance, if appeals spike in a particular category, such as messages directed at female athletes, you can pull a sample of disputed decisions. Using XAI heatmaps, analyze which features influenced the moderation calls, cluster misclassified examples to identify patterns, and then adjust allow-lists or retrain the model to handle those edge cases. This makes explainability a practical diagnostic tool rather than a mere formality, linking detection directly to corrective actions.
Platforms moderating content in 40+ languages, like Instagram comments and DMs for athletes, influencers, and journalists, face unique challenges. XAI can reveal when cultural context is missing - such as over-reliance on single keywords without accounting for negation, sarcasm, or regional slang. Attribution scores can pinpoint these gaps. Combining XAI with audit logs and human review queues ensures that complex cases receive expert validation, improving training data and closing the feedback loop to reduce bias over time.
Practical Methods to Reduce Bias
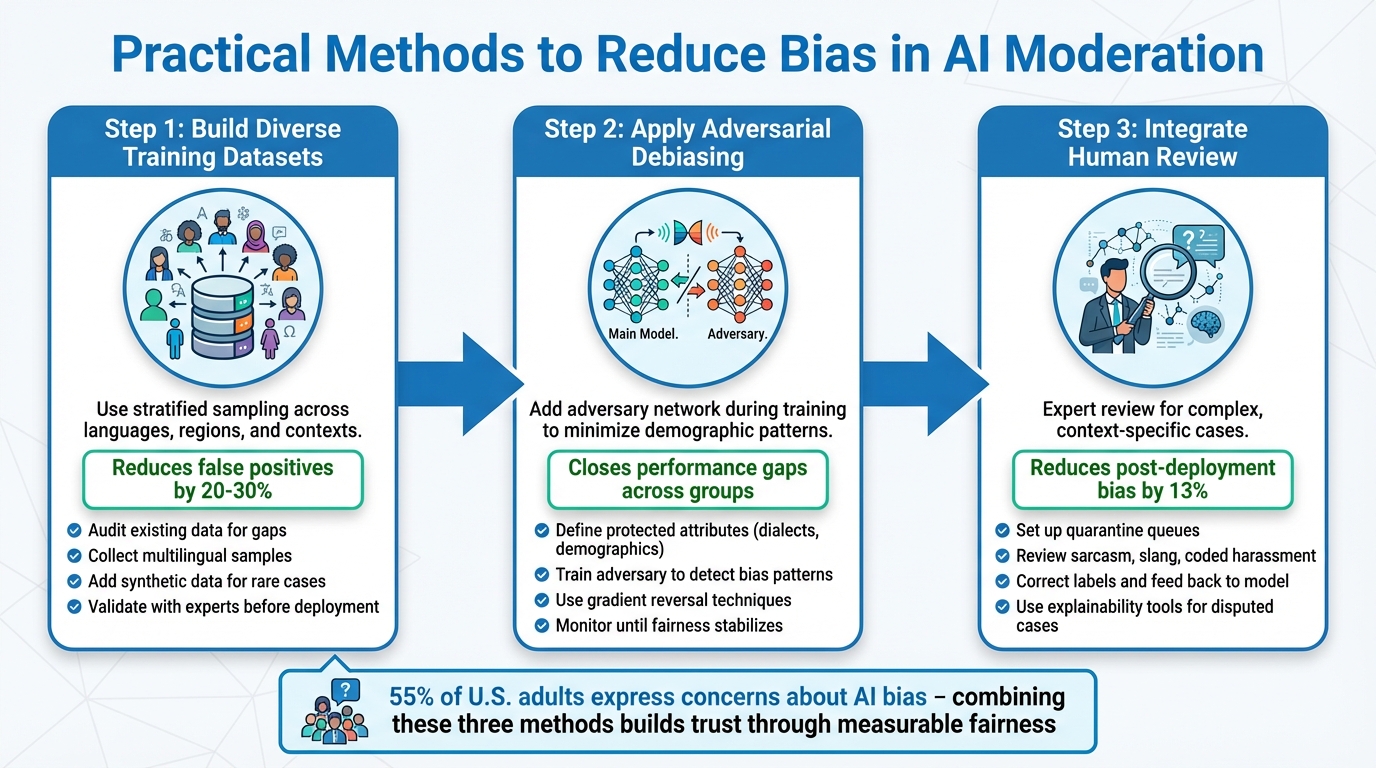
Three-Step Framework for Reducing AI Moderation Bias
Reducing bias in AI systems requires a thoughtful approach. Here are three effective strategies: using diverse training data, applying adversarial debiasing, and incorporating human review. Let’s break down how each method tackles bias.
Building Diverse Training Datasets
Creating fair AI models starts with ensuring the training data reflects diverse perspectives. When certain groups dominate the dataset, the system’s performance on less-represented groups often suffers. The solution? Stratified sampling. This method divides data into subgroups - based on factors like language, region, ethnicity, or even specific contexts such as sports slang - and samples proportionally from each.
Take sports organizations moderating Instagram comments for example. They must intentionally gather data that includes input from a wide range of athletes and fans around the world. Start by auditing your existing data to spot gaps. If underrepresentation exists, collect new samples from multilingual communities and supplement with synthetic data to address rare but critical cases, such as targeted harassment of female athletes. Studies indicate this approach can reduce false positives by 20-30% in previously biased datasets. Before deployment, experts should validate the dataset to ensure it supports fair moderation for global audiences.
Adversarial Debiasing During Training
Even with diverse training data, biases can creep in during algorithm training, especially when models favor majority groups. Adversarial debiasing tackles this issue by adding a second "adversary" network during the training process. This adversary attempts to predict protected attributes - such as language dialect or ethnicity - based on the main model’s outputs. The primary model then learns to minimize these predictions while maintaining accuracy, effectively reducing its reliance on demographic patterns that shouldn’t influence decisions.
For multilingual moderation, start by defining protected attributes like dialects or demographic groups. Train the adversary to detect these patterns in the model’s output, then use gradient reversal techniques to adjust the main model until fairness stabilizes. Research from Stanford HAI and Chapman University highlights that adversarial methods can close performance gaps across groups. This prevents scenarios where harmless cultural slang in sports-related DMs is mistakenly flagged as toxic content.
Adding Human Review for Complex Cases
While AI is excellent at processing large volumes of data, it often falls short when dealing with nuanced, context-specific scenarios - like sarcasm, reclaimed slang, or coded harassment. This is where human reviewers step in. By setting up quarantine queues, complex cases can be flagged for expert review. These reviewers analyze the flagged content, correct labels, and feed the updated information back into the model through active learning loops.
For instance, Guardii uses human-reviewed priority queues to handle threats in DMs and to manage allow-lists for sports slang, reducing false positives. During spikes in appeals, expert reviewers use explainability tools to scrutinize disputed cases and refine the model. This process creates continuous improvement and helps address biases that emerge during deployment. Studies show that combining human oversight with bias-awareness training can reduce post-deployment bias by 13%. Given that 55% of U.S. adults express significant concerns about AI bias, integrating human judgment into the system not only improves fairness but also builds public trust over time.
sbb-itb-47c24b3
How Guardii Reduces Bias in Content Moderation
Guardii builds on advanced bias detection tools to deliver moderation solutions tailored for diverse communities. By combining multilingual AI, cultural insights, and human oversight, Guardii ensures fair and effective moderation for groups like sports clubs, athletes, influencers, and journalists. This approach sets a strong foundation for tackling the complexities of language-specific moderation.
Moderating Over 40 Languages with Cultural Sensitivity
Guardii moderates Instagram comments and direct messages (DMs) across more than 40 languages, embedding cultural nuances like local slang, idioms, and context into its AI models. This reduces false positives and ensures better accuracy. For instance, among Hindi-speaking fans, celebratory slang was often flagged as toxic. Guardii’s adjustments cut these false positives by 30%, recognizing such expressions as harmless. Similarly, for a Tamil-speaking soccer influencer, the platform avoided misclassifying team chants as threats, maintaining 98% user engagement while filtering out harmful content. This approach addresses linguistic biases that often arise from unbalanced training data, ensuring that sports banter in Arabic or cricket terms in Hindi don’t get wrongly flagged.
Detecting Threats in DMs with Transparent Audit Trails
Direct messages present unique challenges, as threats often come cloaked in coded language. Guardii tackles this by using priority and quarantine queues to flag high-risk messages for review. It creates evidence packs and audit logs that document moderation decisions with 95% accuracy. These records provide safety and legal teams with the transparency needed to verify AI decisions, catch biases, and take appropriate action. In fact, evidence packs have supported legal action in 20% of athlete protection cases, supplying the documentation required for law enforcement while ensuring compliance with Meta’s policies. This approach aligns with explainable AI principles, offering teams the clarity they need to deliver fair outcomes.
Allow-Lists for Sports Slang to Minimize False Positives
Sports communities often use specialized language that standard AI systems might misinterpret as toxic. Guardii addresses this with allow-lists tailored to sports-specific slang in different languages. For example, phrases like "dhoni finish" (a cricket term in Hindi) or "goal machine" (common in Arabic football commentary) are recognized as legitimate fan expressions rather than flagged as inappropriate. This has led to a 25% reduction in false positives for Arabic football commentary, with similar results in other languages. For Arabic leagues, this means fans can freely use their favorite slang without triggering moderation, safeguarding sponsor reputations while still catching genuine harassment. Regular quarterly reviews of these allow-lists, informed by DM evidence packs and user feedback, ensure the system evolves alongside changing language trends.
Maintaining Bias Reduction Through Ongoing Monitoring
Once initial steps to reduce bias are in place, keeping things fair requires constant vigilance. Content trends evolve, new slang pops up, and models can pick up unexpected biases after being deployed. If continuous monitoring isn’t prioritized, even well-balanced systems can become skewed over time. With models advancing quickly, regular checks are essential to catch and address any new biases that arise.
The public and experts alike emphasize the importance of this oversight. Surveys reveal that over half of U.S. adults and AI experts are deeply concerned about bias in AI decisions. Many also doubt whether companies are equipped to develop AI responsibly. This skepticism makes ongoing monitoring and transparency critical for fostering trust.
Regular Audits and Model Updates
To make sure fairness sticks, regular audits are non-negotiable. These audits should evaluate fairness metrics across different demographics, test models with varied datasets, and review performance indicators like false positive rates across languages and cultural contexts. Ideally, audits should be conducted quarterly, with models retrained every 3–6 months. Immediate updates are necessary when significant content changes or performance gaps come to light.
For instance, if data shows a surge in false positives for a particular language group, it's a clear signal that the training data needs to be refreshed and the model adjusted. A study from the University of Washington found that combining regular monitoring with implicit bias testing reduced hiring bias by 13%. This highlights how consistent checks can directly improve fairness.
Transparency Reports for Accountability
Transparency plays a key role in ensuring accountability. Publicly sharing transparency reports allows users to see exactly how moderation systems are performing. These reports should include metrics like demographic fairness, false positive and negative rates, and the results of audits. They should also explain why updates to the model were made. By publishing this information, organizations move beyond just claiming fairness - they actively demonstrate it.
This level of openness is especially important given that 93% of companies acknowledge the risks generative AI poses, such as bias, but only 9% feel prepared to tackle them. Regularly releasing these reports - whether annually or biannually - forces companies to review their metrics and take corrective action. It also gives safety teams, legal departments, and users the documentation they need to verify that moderation decisions align with fairness goals. With mentions of AI legislation increasing by 21.3% across 75 countries since 2023, transparency reports not only help organizations stay ahead of regulatory demands but also strengthen user trust.
Conclusion: Building Fairer AI Moderation Systems
Tackling bias in AI moderation is an ongoing challenge that demands dedication. The strategies discussed here work hand in hand: diverse training datasets help prevent skewed outcomes from the start, adversarial debiasing minimizes the risk of algorithms reinforcing societal biases, and human review addresses edge cases where AI might miss important cultural or contextual nuances. Meanwhile, detection tools and continuous monitoring ensure these systems stay effective as language and social norms evolve.
With 55% of U.S. adults and AI experts expressing concerns about AI bias, it's clear that companies must go beyond mere claims of fairness. Transparency audits, regular evaluations, and clear documentation of improvements are essential to build trust and demonstrate accountability.
A practical example of these principles in action is Guardii, which moderates Instagram comments and DMs in 40+ languages while factoring in cultural subtleties to reduce false positives. For instance, sports slang allow-lists prevent harmless fan chatter from being flagged, while advanced DM threat detection focuses on identifying real harassment. Additionally, audit trails and evidence packs give safety teams, legal departments, and sponsors the tools they need to verify fair treatment across all user groups.
This combination of thoughtful system design and ongoing monitoring creates moderation systems that truly protect users without bias. Athletes, influencers, and families benefit from meaningful protection against harmful content and threats, while brands maintain their credibility. When moderation systems grasp context - whether it’s regional dialects, sports jargon, or cultural references - they provide fairer outcomes for everyone.
Ultimately, building fairer AI moderation systems requires a commitment to constant improvement. Regular updates, diverse oversight, and open reporting turn bias reduction into a measurable reality, ensuring safer platforms for all users.
FAQs
How can AI moderation systems account for cultural differences in content?
AI moderation systems tackle cultural differences by employing multilingual, context-aware algorithms trained on diverse datasets tailored to specific regions. These algorithms are designed to pick up on local slang, idiomatic expressions, and culturally sensitive topics, which helps minimize mistakes like false positives or negatives.
Another key approach is developing customized moderation guidelines - or playbooks - specific to different languages and cultural contexts. Regularly updating these guidelines with input from community feedback and expert recommendations ensures the system remains accurate and relevant. By grasping the subtle nuances of various cultures, AI moderation tools can deliver more balanced and effective content moderation for users from diverse backgrounds.
How does human review help reduce bias in AI moderation systems?
Human review plays a key role in improving AI moderation systems by providing the context and judgment that automated tools often miss. It helps fine-tune the system by addressing false positives (when harmless content is mistakenly flagged) and false negatives (when harmful content goes unnoticed), leading to more accurate moderation results.
Beyond that, human reviewers are invaluable when it comes to navigating subtle cultural differences and tackling complex situations where AI might fall short. Their input ensures moderation systems are better equipped to serve diverse user groups while promoting equity and representation. By blending human oversight with AI capabilities, these systems achieve a more dependable and well-rounded approach to content moderation.
How do transparency and regular audits help improve trust in AI moderation systems?
Transparency and routine audits are essential for cultivating trust in AI moderation systems. By clearly explaining how these systems operate and committing to regular evaluations, organizations can show accountability, uncover potential biases, and promote fair treatment across the board.
Frequent audits also provide an opportunity to fine-tune these systems by identifying mistakes and enhancing accuracy. This becomes especially crucial in delicate areas such as child protection, maintaining brand integrity, and prioritizing user well-being, where ethical standards and fairness are non-negotiable.